
Speech as an Art form
- If we closely observe ourselves, each one of us can effectively manipulate a mundane activity like exhalation and turn it into meaningful art forms of self-expression either in the form of speech or singing.
- Like self-expression, imitation is also considered an art and we appreciate great artists, who can successfully do so. But could such skills be used to forge biometric security systems?
- ASR has developed from IBM’s Shoebox to today’s Siri on an iPhone. Could voice-based recognition system that we use to access our phone today be as reliable as we think?

Figure 1 The IBM Shoebox, introduced in 1962, could understand 16 words: zero, one, two, three, four, five, six, seven, eight, nine, minus, plus, subtotal, total, false, and off
Speech generation mechanism
Human speech generation system utilizes two main structures
- Vocal folds – Generates the pitch of the voice containing prosodic or emotional content.
- Vocal Tract (Resonating Chamber) – Is structurally unique for each person and hence gives a unique spectral color.
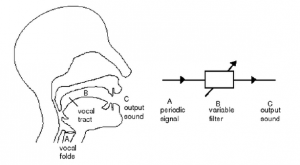
Figure 2 Speech generation mechanism
Imitation an example
- A well-popularized demonstration of imitation could be seen in the movie Jurassic Park III, where the palaeontology student of Dr. Alan Grant, Billy Brennan hands over a 3D printed model of the resonating chamber of the fossilized velociraptor.
- Dr. Grant in a later part of the movie defends himself by blowing into the chamber imitating the most feared predator among the other breeds.

Figure 3 Imitation an example as mentioned in Dr. Kuang-Hua Chang Book on – eDesign Computer Aided Engineering Design
Speaker recognition system
- The performance of any speaker recognition system heavily depends on the choice of discriminating features we train it to familiarize with.
- Mel Frequency Cepstral Coefficients (MFCC) mathematical models the human ear, by modelling the non-linear perception of frequency and intensity using a mel scale and a logarithmic scale.
- The timbre of sound or unique spectral color of one’s voice is extracted from the voice recording within these features.
- The brain of such systems can be a Gaussian Mixture Model as an example.
Figure 4 Voice recognition system
Types of Forging
- Playback Attack
Answering simple questions over the phone like ‘Yes’, ‘ok’ can make you a victim if you are not careful.
- Human Imitation
Mimicry artists are said to have an impact in forging to an extent
- AI-based Imitation
Montreal based AI startup Lyrebird is a speech generator that can fake anyone’s voice and is working towards perfecting it.
Sources
References